
Introduction
Oggi è possibile osservare immagini create con algoritmi come la Diffusione stabile. Ma sintetizzare i video utilizzando l'intelligenza artificiale è un processo molto più complesso. Come persona che ha lavorato in aziende di produzione di media, posso dire con certezza che la creatività generata dall'intelligenza artificiale non ha ancora raggiunto la qualità necessaria per diventare virale.
C'è una grande differenza tra i video generati dall'intelligenza artificiale e gli standard del settore. La diffusione stabile non si limita alla creazione di immagini statiche; con alcuni strumenti ed estensioni, è possibile creare video AI di grande impatto visivo. Ecco una semplice guida per creare una GIF animata o un fotogramma video utilizzando la Diffusione stabile.

In questo articolo
La diffusione stabile può generare video?
Sì, è possibile creare video o file GIF con una distribuzione stabile. La nuova funzione img2img consente di creare brevi video o GIF che sembrano filmati. La tecnologia AI può essere utilizzata anche per fornire rapidamente fotogrammi animati per i video.
È inoltre possibile utilizzare strumenti dedicati per creare video utilizzando la piattaforma Stable Diffusion. Questi strumenti possono essere utilizzati per creare video MP4 utilizzando l'interfaccia web.
La diffusione stabile è buona?
L'affidabile generazione di video di diffusione è un ottimo strumento per creare foto colorate e realistiche. Anche se l'uso di questa sostanza può avere degli svantaggi, i benefici sono superiori agli svantaggi. La sua praticità, la versatilità e i risultati sorprendenti rendono Stable Diffusion un must per tutti coloro che amano le immagini convincenti.
Stable Diffusion è una grande risorsa per chi vuole ampliare le proprie capacità artistiche. Può aiutarvi a trovare l'ispirazione per un nuovo progetto o a esplorare diversi stili e tecniche visive.
L'interfaccia intuitiva consente di creare immagini in base alle proprie esigenze.
Non è necessario essere un artista esperto per utilizzare questa funzione, che è facile da usare per persone di ogni livello. Con una diffusione affidabile, è possibile liberare la propria creatività e produrre immagini e disegni straordinari da mostrare.
Come funziona la diffusione stabile?
L'idea di base della generazione di immagini con modelli di diffusione si basa sul fatto che i modelli di computer vision avanzati possono essere addestrati con una quantità sufficiente di dati. La diffusione stabile offre un approccio potente a questo problema, utilizzando un algoritmo che genera immagini in base a parametri specifici.
L'algoritmo di generazione della diffusione in stato stazionario utilizza una speciale tecnica di diffusione per generare video con un'immagine di rumore casuale in continuo miglioramento. Il risultato è un'opera visivamente accattivante, ad alta risoluzione, che sembra creata da un artista esperto. Ecco la procedura:
1. Partenza verso lo spazio latente:
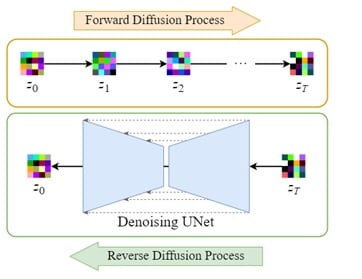
Il processo inizia con l'addestramento dell'autocodificatore per codificare l'immagine in una rappresentazione latente a bassa dimensione. Possiamo quindi utilizzare il codificatore addestrato E per convertire l'immagine originale in una versione compressa più piccola. D, un decodificatore addestrato, può ricostruire l'immagine originale dai dati latenti.
2. Diffusione latente:
Il processo di ulteriore diffusione aggiunge rumore ai dati latenti codificati, mentre il processo di retrodiffusione rimuove questo rumore dagli stessi dati. Questo assicura che le immagini possano essere riportate alla loro forma originale.
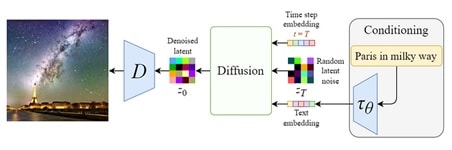
3. Condizionamento:
Un robusto modello di generazione video distribuita utilizza la capacità di generare immagini da chiamate di testo, integrando il denoising della rete U con un meccanismo di controllo incrociato.
Ciò avviene fornendo al modello interno input condizionati, come modulazioni testuali generate da modelli linguistici (ad esempio BERT o CLIP) e altri input spaziali (ad esempio immagini o mappe). A seconda del tipo di input di condizionamento, esso viene mappato nella rete U tramite lo strato di attenzione o aggiunto tramite concatenamento.
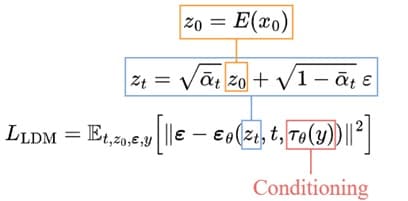
4. Formazione e campionamento:
Lo scopo dell'addestramento è simile a quello del modello di diffusione di base, ma con alcune modifiche. Invece delle immagini xₜ, prendiamo i dati latenti zₜ e la griglia U include l'input condizionante 𝜏θ(y). Poiché i dati latenti sono molto più piccoli della foto originale, il processo di denoising è molto più veloce.
Come si fa a creare un video che si diffonda in modo affidabile?
Deforum Stable Diffusion è una versione speciale di Deforum progettata per creare videoclip e transizioni utilizzando le immagini generate da Stable Diffusion. Chiunque può utilizzare questo strumento software open source, basato sulla comunità, indipendentemente dal livello di competenza o dall'esperienza.
Se siete interessati a partecipare a un progetto, gli sviluppatori sono sempre felici di accettare nuovi contributi. La pipeline Generate stable diffusion video di Deforum consente di creare una simulazione completa senza utilizzare la GPU.
• Generare un video utilizzando Deforum
Per copiare Deforum Stable Spread Generation Video v0.5 su Google Drive, fare clic sul pulsante "Copia su Drive". Verrà inviata una nuova copia del blocco note Colab a Google Drive e si potrà chiudere il blocco note originale perché non serve più.
• Passo 1: Installare l'estensione Deforum
Sfruttate al massimo il vostro attuale Google Colab e collegatelo a una GPU esterna. Google Colab è disponibile con crediti gratuiti, ma tenete presente che quando si esauriscono, dovrete acquistarne altri o aspettare qualche giorno per ripristinarli.
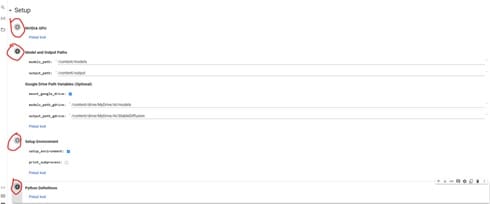
• Passo 2: Scrivere i suggerimenti
Al giorno d'oggi, è sempre più importante utilizzare il modello della generazione video a diffusione stabile (o un altro LLM) quando si progettano o sviluppano tecnologie di comunicazione.
Per ottenere l'effetto desiderato, vi consigliamo di fornire istruzioni dettagliate e specifiche quando create le vostre immagini. È inoltre importante visualizzare in anteprima tutte le impostazioni o gli effetti di animazione che si desidera utilizzare, come l'illuminazione, il tempo, lo stile artistico o i riferimenti culturali.
Sebbene sia importante evitare di intitolare le opere o di omettere il nome dell'artista, alcuni progetti possono produrre risultati interessanti. Quando si crea un'animazione, è necessario prevedere sempre una prima chiamata e altre chiamate prima di iniziare.
Provate prima i comandi e poi utilizzate quello che funziona meglio nell'animazione finale. Con le tecniche giuste, i creatori possono ottenere l'effetto desiderato per un'animazione di successo.
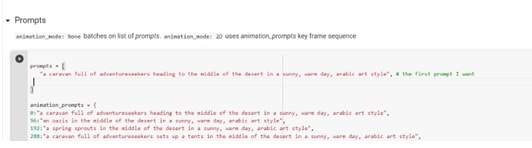
• Passo 3: Regolare le impostazioni di Deforum
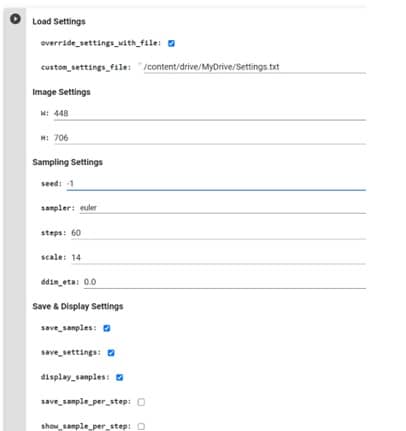
Si consiglia di utilizzare l'opzione override_with_file per i video stabili e distribuiti, in modo che le impostazioni vengano sempre salvate e possano essere riutilizzate, condivise o annullate. Per le immagini in formato 9:16, provare con 448 x 706; per le immagini verticali, 706 x 448; per le immagini quadrate, 512 x 512.
Nelle impostazioni di campionamento, inserire un numero nella riga Seme se si desidera un'immagine specifica, oppure -1 se si desidera un'immagine casuale. Per il valore del passo, si suggerisce un intervallo compreso tra 50 e 60. Infine, il valore di scala può essere impostato tra 7 e 12.
•Passo 4: Creare il proprio video
Il passo finale dopo la creazione del video è scaricare le immagini e inserirle nel software di editing video appropriato prima di renderizzare il video. Un software gratuito a questo scopo è Da Vinci Resolve 18, che offre una serie di funzioni per un maggiore controllo sul risultato finale.
In alternativa, è possibile utilizzare il codice 'crea filmato da fotogrammi', ma non sempre si ottiene il risultato desiderato.
Come scrivere chiamate di distribuzione credibili
Se avete mai usato strumenti di generazione di immagini AI come Stable Diffusion, DALL-E o Midjourney, saprete quanto sia importante essere precisi nella formulazione dei comandi. Richiami precisi ed esaurienti possono trasformare qualsiasi idea in qualcosa di straordinario, ma una formulazione vaga può trasformarla in qualcosa di bizzarro e inquietante. Ecco alcuni suggerimenti:
1. Essere specifici: Crea un video virale affidabile può avere successo se vengono fornite istruzioni specifiche, paragonabili a un Midjourney più aperto. Per creare un paesaggio di diffusione stabile, è necessario descriverlo dettagliatamente nella guida, utilizzando parole che descrivano accuratamente l'immagine che si desidera creare.
Sperimentate con frasi diverse e vedete quali risultati ottenete. È una buona idea osservare come la modifica di poche parole chiave possa cambiare drasticamente l'immagine e rifletterla nelle chiamate all'azione per ottenere i risultati desiderati.
2. Assicuratevi dello stile artistico e della creatività: Oltre a visualizzare il contenuto dell'immagine desiderata, è necessario specificare anche lo stile desiderato. Ad esempio, se si desidera qualcosa che assomigli a una vernice acrilica, il comando dovrebbe essere qualcosa come "Nome, vernice acrilica" o "Nome, stile acrilico."
Questa formula offre le migliori possibilità di avvicinarsi allo stile desiderato. Distribuzione stabile di forme e stili diversi, compresi disegni a matita, modelli in argilla e rendering 3D in Unreal Engine.
3. Includere il nome dell'artista per maggiore chiarezza:La diffusione stabile è una buona scelta se si vuole evocare lo stile di un particolare artista nel proprio lavoro. Con i giusti inviti all'azione, è uno strumento potente per catturare veramente l'essenza di un particolare artista.
È anche possibile combinare diversi artisti per creare una fusione di stili unica. Questi esperimenti artistici possono produrre risultati interessanti e inaspettati, quindi non abbiate paura di cimentarvi nella creazione di un video virale.
4. Analizzare le parole chiave: Se avete bisogno di enfatizzare alcune parole chiave nelle vostre chiamate, Stable Spread offre un'opzione di ponderazione. Questa funzione consente di attribuire ad alcune parole un significato maggiore rispetto ad altre per ottenere risultati più accurati. Questo è particolarmente utile quando l'output è quasi esatto, ma sarebbe utile se si prestasse maggiore attenzione al termine specifico.
5. Altri riferimenti: Di recente, la quantità di arte dell'intelligenza artificiale disponibile su Internet è aumentata notevolmente. Tutti creano opere di questo tipo e queste storie contengono le parole chiave o le formule utilizzate per crearle. Mostra che sul web potrebbero esserci milioni di immagini generate dagli utenti.
Impostazioni tecniche aggiuntive per generare l'acceleratore:
Quando si utilizza la diffusione allo stato stazionario, è più difficile creare un richiamo efficace, ma anche la modifica di altre impostazioni può avere un impatto significativo sui risultati.
- CFG: Questo parametro determina il livello di fiducia nella capacità di Stable Diffusion AI di generare risposte che riflettano accuratamente i comandi dell'utente. Valori più alti consentono all'IA di generare comandi più veritieri, mentre valori più bassi danno all'IA maggiore libertà di agire in modo indipendente nel testo generato. Provare diversi valori per vedere quale gamma di uscita si ottiene.
- Approccio di campionamento: Dopo la rimozione delle interferenze, l'immagine viene trasformata in un modello identificabile utilizzando vari algoritmi come Euler_a, k_LMS, PLMS, ampiamente utilizzati per la generazione di video a diffusione stabile.
- Tappe di campionamento: Il numero di iterazioni per raggiungere la versione finale di un'immagine può variare. In generale, un numero minore di passaggi darà risultati soddisfacenti, mentre un numero maggiore di passaggi potrebbe non dare ulteriori miglioramenti. Si consiglia di iniziare con un numero relativamente basso di passi e di aumentare gradualmente il numero di passi secondo le necessità. Di solito non si ottengono ulteriori miglioramenti dopo 150 iterazioni.
Conclusione
La creazione di video in tempo reale con generazione di video virali affidabili può essere piuttosto complessa e richiedere molto tempo. Ma con lo sviluppo della tecnologia, speriamo che alla fine sarà più facile creare video con la stessa distribuzione stabile di oggi. Tuttavia, fino a quando questi progressi non saranno compiuti, gli utenti saranno costretti a utilizzare una serie di sottostrumenti e comandi che potrebbero non essere compresi da tutti gli utenti.
FAQ
-
È possibile animare con Stable Diffusion?
Ci sono diversi modi per creare animazioni. Stability AI consente agli utenti di utilizzare i suoi modelli di Diffusione Stabile, come Stable Diffusion 2.0 e Stable Diffusion XL, per la creazione di animazioni. Gli utenti potranno anche utilizzare l'endpoint dell'animazione per accedere a modelli già pronti per creare rapidamente animazioni in massa. -
Che cosa può generare la diffusione stabile?
Stable Diffusion è un generatore di immagini AI che potete personalizzare a vostro piacimento. Esistono piattaforme open source che consentono la creazione di insiemi di dati e la personalizzazione delle immagini generate. È anche possibile addestrare il modello a creare l'immagine giusta per quella desiderata. -
La diffusione stabile è solo per le immagini?
La diffusione stabile è un modo per generare immagini da descrizioni testuali. È una scelta migliore rispetto al mid-journey e al DALLE-2 perché è in grado di visualizzare accuratamente il testo. Ciò avviene grazie a sofisticati algoritmi e reti neurali convoluzionali che convertono i contenuti scritti in immagini corrispondenti.
