100% sicuro e download gratuito
100% sicuro e download gratuito
Qualsiasi utente Linux conosce il potenziale fastidio che le righe vuote possono causare in un file processabile. Oltre a ostacolare l'elaborazione di tali file, queste righe vuote rendono difficile per il software in esecuzione leggere e scrivere sul file. In questo articolo vedremo alcuni metodi rapidi perrimuovere le righe vuote in Bash su Linux.
Per semplificare l’argomento, parleremo di 6 possibili approcci e analizzeremo alcuni casi pertinenti con le necessarie giustificazioni. Useremo diversi comandi ed esempi per cancellare le righe vuote dal file e visualizzare il file.
6 Metodi per Rimuovere le Righe Vuote in Bash su Linux
Le 6 tecniche elencate di seguito verranno usate per rimuovere le righe vuote in Bash su Linux. Prima di iniziare, vediamo quali sono le loro funzioni:
- comando sed: Editor di flusso per filtrare e manipolare il testo.
- comando grep: Visualizza le righe che corrispondono ai modelli.
- comando awk: L'utilità awk esegue programmi scritti nel linguaggio awk, pensato per manipolare dati testuali.
- comando cat: Unisce file e li stampa sull'output standard.
- comando tr: Traduce o rimuove i caratteri.
- comando perl: Un linguaggio di programmazione creato specificatamente per la modifica del testo.
Metodo 1: Esegui il comando sed per rimuovere le righe vuote in Bash
Nella nostra prima soluzione, useremo il comando sed per rimuovere le righe vuote in Bash dal file. Il comando sed viene utilizzato per semplici modifiche di testo.
- L’editor di flusso sed può rimuovere le righe vuote dai file, come mostrato di seguito.
sed '/^[[:space:]]*$/d' 1_Test.txt
- Quando esegui lo script Bash sopra menzionato, dovresti vedere un output simile al seguente:
Questa è la prima riga.
Questa è la seconda riga.
Questa è la terza riga.
Questa è la quarta riga.
Dove:
'/[[:space:]]*$/d':Questa parte del codice viene utilizzata per trovare e cancellare le righe vuote dal file.//:La stringa di ricerca è memorizzata qui.^:Inizio della stringa.$:Fine della stringa.d:Rimuove la stringa corrispondente.txt:Nome del file sorgente.
Metodo 2: Rimuovere le righe vuote in Bash usando il comando grep
Grep sta per Global Regular Expression Print. Possiamo facilmente rimuovere le righe in Bash con il comando grep, un altro strumento integrato in Bash. Il testo e le stringhe di un file fornito vengono ricercati e il programma restituisce ogni riga che corrisponde ad un modello.
- Puoi usare questa tecnica per cancellare le righe vuote dal file seguendo l’esempio qui sotto.
grep -v '^[[:space:]]*$' 1_Test.txt
- L’output dell’esecuzione dello script Bash sopra sarà simile a questo:
Questa è la prima riga.
Questa è la seconda riga.
Questa è la terza riga.
Questa è la quarta riga.
I dettagli sono i seguenti:
'[[:space:]]*$':Una parte del codice serve per trovare e cancellare le righe vuote dal file..:Sostituisce qualsiasi carattere^:Inizio della stringa$:Fine della stringaE:Per confrontare i modelli nelle espressioni regolari estese.e:Per il pattern matching nelle espressioni regolari.v:Per selezionare tutte le righe che non corrispondono al file.txt:Nome del file sorgente
Metodo 3: Usa il comando awk per rimuovere le righe vuote in Bash
In questo metodo sfrutteremo awk, una parola chiave integrata nello script Bash. Awk è un linguaggio di scripting generico creato per l'elaborazione sofisticata di dati testuali. La manipolazione del testo, la creazione di report e l'analisi sono i suoi usi principali.
- L’esempio sotto mostra come rimuovere le righe vuote dal file usando questa parola chiave.
awk '!/^[[:space:]]*$/' 1_Test.txt
- Ed ecco l’output:
Questa è la prima riga.
Questa è la seconda riga.
Questa è la terza riga.
Questa è la quarta riga.
Dove:
/[[:space:]]*$/:La sintassi consente di riconoscere e rimuovere le righe vuote in un file.//:La stringa di ricerca è memorizzata qui.^:Inizio della stringa$:Fine della stringa.:Sostituisce qualsiasi carattere!:Rimuove la stringa che corrisponde.txt:Nome del file sorgente
Metodo 4: Esegui il comando cat per rimuovere le righe vuote in Bash
Cat è l’abbreviazione di concatenate. È comunemente utilizzato in Linux per leggere dati da un file. Nei sistemi operativi di tipo Unix, il comando cat è uno dei più usati. Offre tre funzioni legate ai file di testo: mostra il contenuto del file, combina più file in un'unica uscita e crea un nuovo file.
- Possiamo facilmente rimuovere le righe vuote da un file combinando i comandi 'cat' e 'tr' come mostrato di seguito:
Cat 1_Test.txt | tr -s '\n' > new_file.txt
- Output:
Questa è la prima riga.
Questa è la seconda riga.
Questa è la terza riga.
Questa è la quarta riga.
Le specifiche sono le seguenti:
|:Il simbolo della pipe. Usa l’output del primo comando come input per un altro comando.s:Sostituisce ogni sequenza di un carattere ripetuto nell’insieme specificato per ultimo.\n:Per inserire una nuova riga.txt:Nome del file sorgente.
Metodo 5: Rimuovere le righe vuote in Bash usando il comando tr
In Linux e sui sistemi Unix, tr è un’utilità da riga di comando che traduce, elimina e compatta caratteri dall’input standard e scrive i risultati sull’output standard. Il comando tr può togliere caratteri ripetuti, convertire maiuscole in minuscole e fare sostituzioni e rimozioni di base sui caratteri. Di solito è utilizzato insieme ad altri comandi tramite piping.
- Comprimi i caratteri di a capo ripetuti per rimuovere le righe vuote:
tr -s '\n'< file.txt > new_file.txt
Nel comando sopra, abbiamo utilizzato:
<:Questo simbolo di reindirizzamento viene usato per passare il contenuto di file.txt al comando tr.>:Simbolo di reindirizzamento che scrive l’output del comando in new_file.txt.
Metodo 6: Usa il comando perl per rimuovere le righe vuote in Bash
Perl è l’abbreviazione di Practical Extraction and Reporting Language. Perl è un linguaggio di programmazione creato specificatamente per la modifica del testo. Ora è ampiamente utilizzato per varie attività, come l’amministrazione dei sistemi Linux, la programmazione di rete, lo sviluppo web, ecc.
- L’esempio qui sotto mostra come usare questa parola chiave per rimuovere una riga vuota da un file.
perl -ne 'print if /\S/' 1_Test.txt > new_file.txt
- Ed ecco il risultato:
Questa è la prima riga.
Questa è la seconda riga.
Questa è la terza riga.
Questa è la quarta riga.
Dove:
.:Può essere usato per sostituire qualsiasi carattere.^:Inizio della stringa.$:Fine della stringa.E:Per il pattern matching con espressioni regolari estese.e:Pattern matching per le espressioni regolari.v:Estrae le righe non corrispondenti da un file.txt:Nome del file sorgente.
Come Recuperare File Eliminati Accidentalmente in Linux
Ora che abbiamo discusso sei metodi diversi per rimuovere le righe vuote in Bash su Linux, è importante ricordare che possono capitare incidenti e a volte file importanti possono essere eliminati accidentalmente. Fortunatamente, esistono modi perrecuperare i file eliminati in Linux.
Una soluzione molto consigliata è usare Wondershare RecoveritRecupero Dati Linux. Questo potente software di recupero dati è progettato specificatamente per i sistemi Linux e può recuperare rapidamente e facilmente file cancellati, anche se eliminati definitivamente dal cestino.

Wondershare Recoverit - Il tuo software sicuro e affidabile per il recupero dati su Linux
5.481.435 persone lo hanno scaricato.
Recupera documenti, foto, video, musica, email e altri oltre 1000 tipi di file persi o cancellati in modo efficace, sicuro e completo.
Compatibile con tutte le principali distribuzioni Linux, tra cui Ubuntu, Linux Mint, Debian, Fedora, Solus, Opensuse, Manjaro, ecc.
Assiste in oltre 500 scenari di perdita di dati, come eliminazione, formattazione del disco, crash del sistema operativo, interruzione di corrente, attacco di virus, partizione persa e molti altri.
L'interfaccia semplice punta-e-clicca ti permette di recuperare dati da dischi rigidi Linux in pochi clic.
Funziona tramite una connessione remota. Puoi recuperare dati persi anche quando il tuo dispositivo Linux è in crash.
Il recupero dati Linux è davvero facile e senza problemi con Wondershare Recoverit. I tuoi dati possono essere recuperati in 3 semplici passaggi.
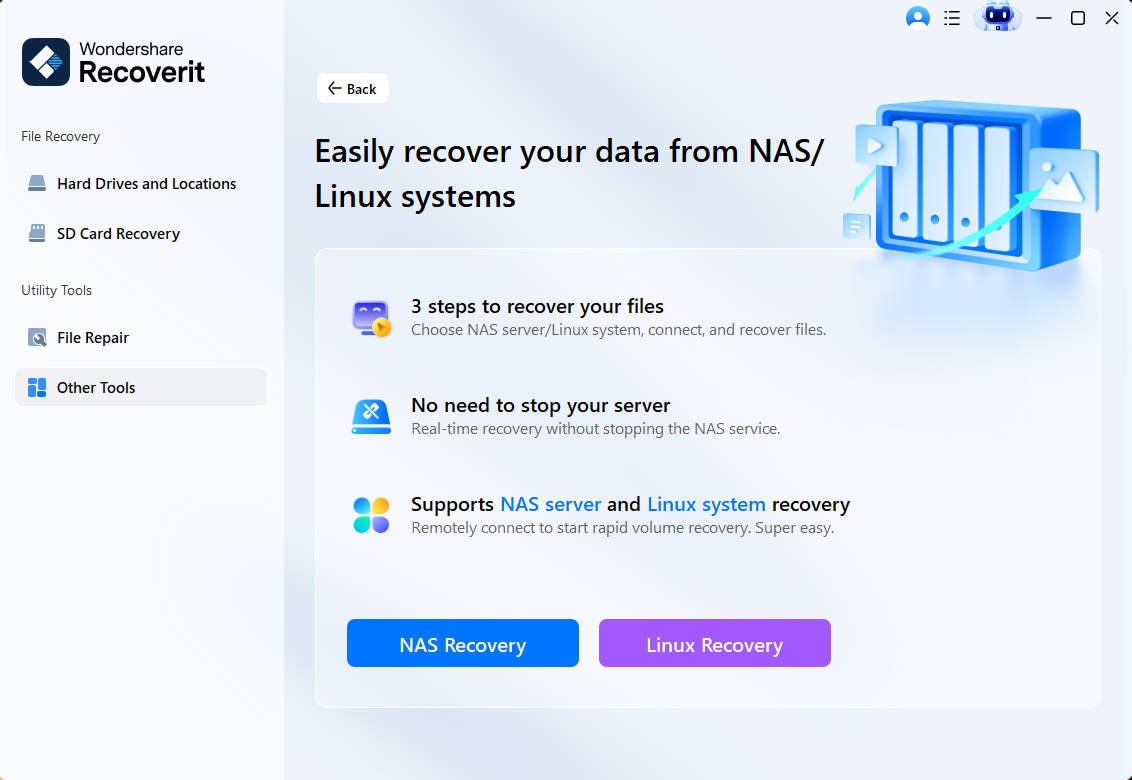
Passaggio 1Scegli Recupero Linux
Scarica e installa Wondershare Recoverit sul tuo computer. Apri il software, poi seleziona NAS e Linux. Per continuare, fai clic sull'opzione Recupero Linux.
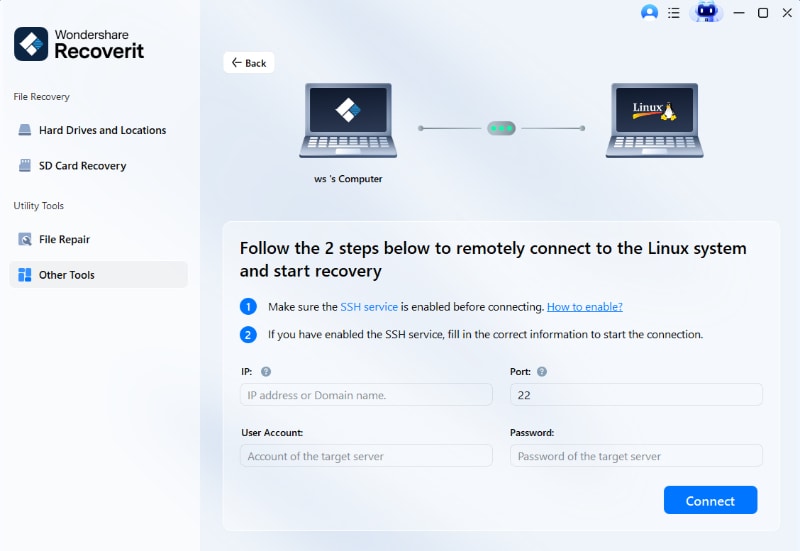
Passaggio 2Connetti Remotamente il Computer Linux
Come mostrato di seguito, si aprirà una nuova finestra sullo schermo. Inserisci i dati richiesti per stabilire una connessione remota. Una volta terminato, fai clic sul pulsante Connetti.
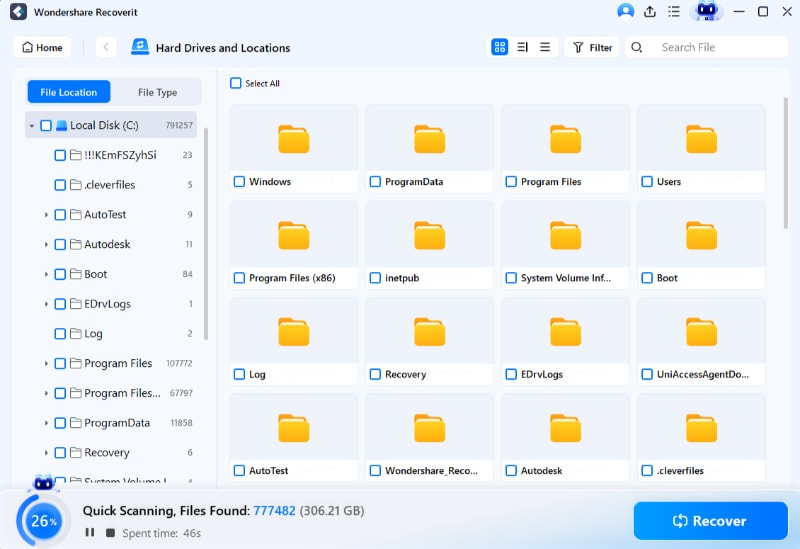
Recoverit eseguirà automaticamente la scansione per cercare i tuoi file mancanti in un computer Linux una volta che la connessione è stata stabilita con successo.
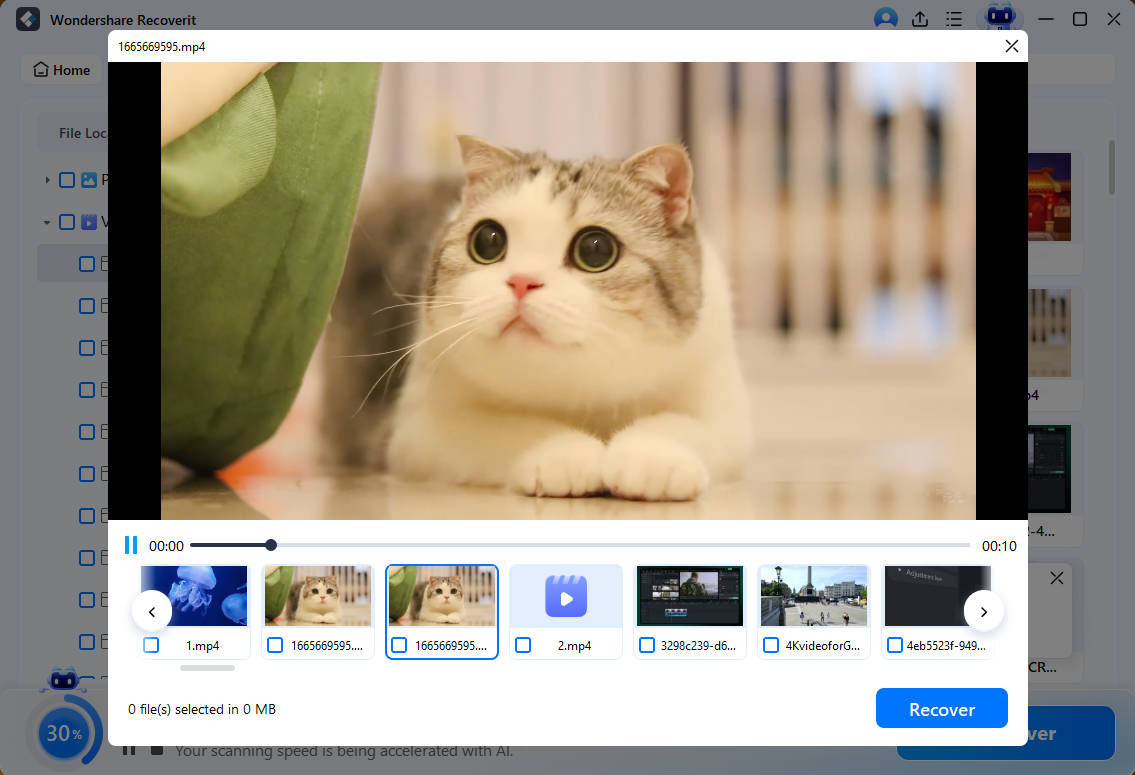
Passaggio 3Anteprima e Recupero
La parte migliore di Recoverit è che puoi interrompere la scansione in qualsiasi momento quando trovi il file che vuoi ripristinare. Puoi visualizzare l'anteprima dei file per assicurarti che siano quelli che desideri recuperare. Per salvare i file desiderati, selezionali e fai clic ora sul pulsante Recupera.
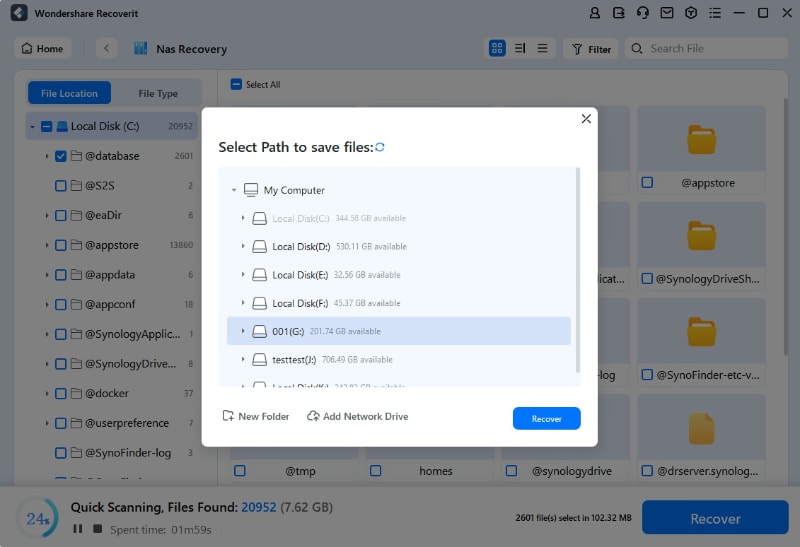
Il software ti chiederà di selezionare la posizione in cui desideri conservare i file recuperati. Per ottenere i dati ripristinati, fai clic su Recupera.
Per Windows Vista/7/8/10/11
Per macOS X 10.10 o versioni successive
Per Riassumere
Abbiamo discusso i sei metodi per rimuovere le righe vuote in Bash su Linux e, in caso di perdita accidentale dei dati, Wondershare Recoverit Linux Recovery è un software consigliato per recuperare i tuoi dati in modo sicuro e senza problemi!